Environment
Retain
Situation
Resolution
Retain is capable of archiving billions of items, and the biggest bottlenecks are usually the network and disk speeds. As organizations grow from hundreds of mailboxes to thousands of mailboxes they tend to deploy a cluster of mailbox servers.
Retain doesn't cluster in a way that allows you to run multiple Retain servers that work in parallel, but what you can do is distribute the various functions across a cluster of servers to increase performance.
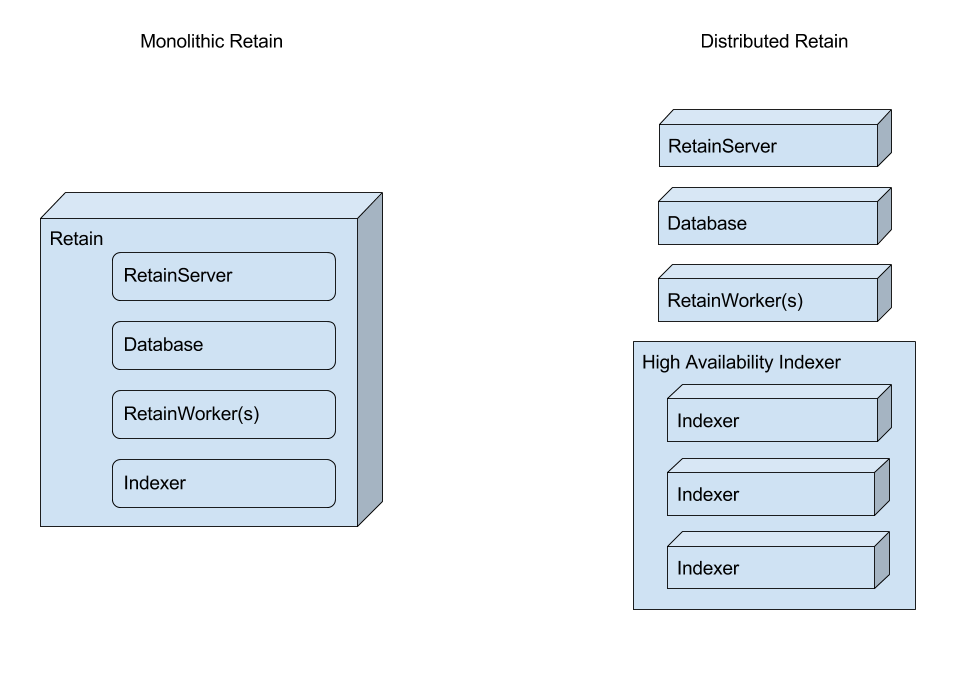
Retain is made up of a number of functions:
- RetainServer: manages storing the items to disk
- RetainWorker: retreives the items from the email system
- Database: holds the address book and pointers to the items on disk
- Indexer: is the search engine for finding items in Retain
You can transition Retain from a monolithic architeture to a distributed architecture.
You can move the Worker, Database and Indexer to separate servers to increase performance, but it requires that your network backbone be really fast. The advantage here is that the Worker will generate a hash for the item and ask the RetainServer if the RetainServer has it. If the RetainServer replies that it already has the item the RetainWorker drops the item and continues to the next item, otherwise the worker sends the item to RetainServer for further processing. This can save on network bandwidth as the Worker only has to transmit new items and not every item. We recommend 1 Worker for each PO or mailbox database in your email system. You can place a Worker on each mailbox server or on a dedicated Worker server.
If you have a email server cluster, it is likely you have a database server cluster and you can move the Retain database into your database cluster. This needs to be handled by your database administrator.
Retain 4.0 comes with a new high performance indexer built-in as the standard indexer. This provides a more powerful search engine for Retain. It can be moved off of the Retain server and onto a dedicated indexing cluster for High Availability Indexing. This requires a separate license and at least 3 dedicated indexing servers.
The toughest call to make is with the disk system. Usually you will have the fastest network you can buy, but with an archive solution you can save some money by using slower disks because it is an archive solution which will probaly not be used too much. But sometimes during an information request there will be lots of random reads and with slow disks that may take some time. This is why it is important to have the different functions of Retain on different physical disks at least. The IO subsystem can get bogged down because during a job the server will be writing files to disk, the database will be reading and writing to disk and the indexer will be writing to disk as well.