Environment
Retain Server on:
Linux
Windows
Indexing Engine:
Lucene
Exalead
Situation
How do I configure which file types are indexed in Retain? How do I change how much of the file is indexed?
Resolution
Introduction
Retain provides the ability to search for keywords in the message body and attachments of an email. This is made possible by indexing the email parts with index engines such as Lucene and Exalead.
Before an attachment can be sent to an indexing engine, its words must be extracted into plain text. Since each file type varies in the way its data is encoded, a different text extractor is usually required for each file format. Therefore, the number of file types which can be indexed is dependent on the amount of compatible text extractors.
Configuring the Index
The index configuration can be found in the RetainServer web page under Server Configuration -> Index
Note: This section of Retain should be edited with caution. Any misconfiguration could result in attachments not being indexed and therefore would not be searchable in Retain.
Note: The 'Add' or 'Delete' buttons should not be used unless directed by technical support.
The figure below is a screen shot of the index configuration in Retain. Each row in the table represents a different file type which can be indexed. The columns are the indexing options for each file type.
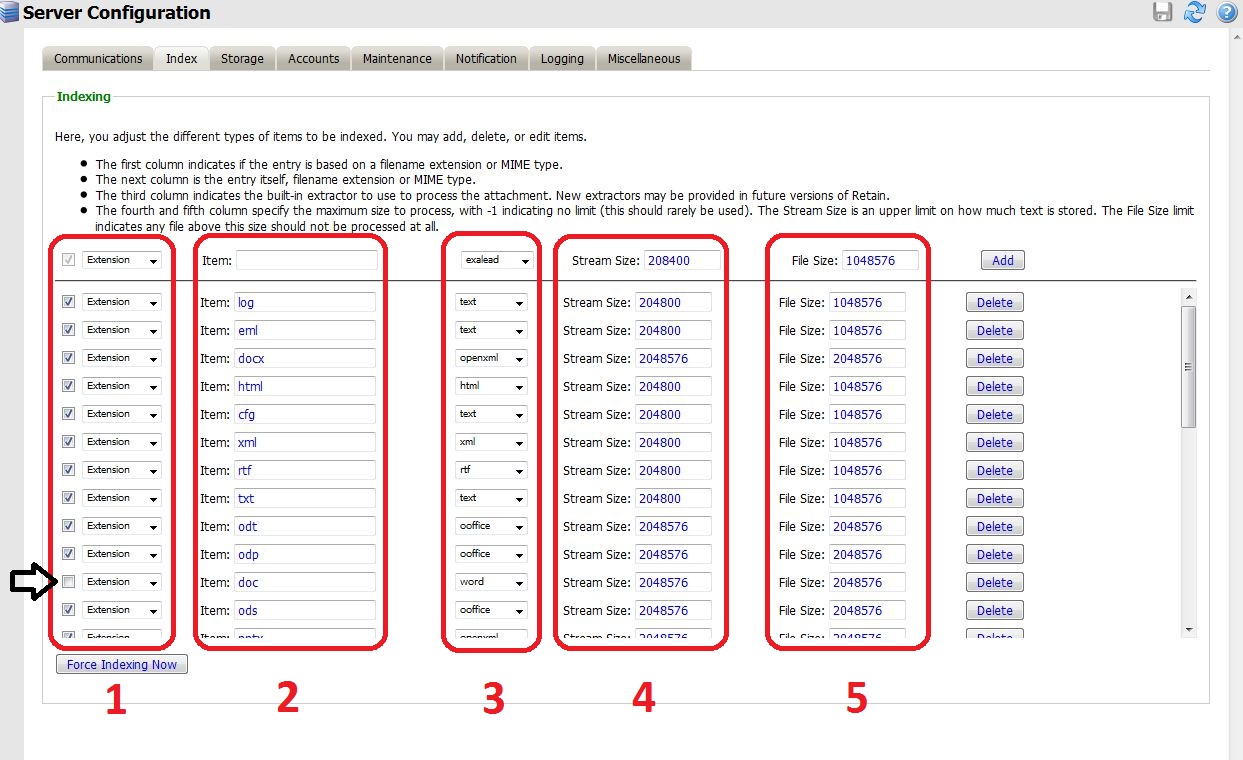
- COLUMN 1:
The checkboxes here enable and disable indexing of the file type. For example, in the figure above, any Microsoft DOC files will NOT be indexed since the box is not checked. The value in the drop down menu next to the checkbox should not be altered. It indicates whether the file is embedded in the MIME.822 or should be recognized by its extension.
- COLUMN 2:
This column specifies the extension name of the file type. These values should NOT be changed.
- COLUMN 3:
The drop down menu in this column specifies which extractor will be used with each file type. These settings should NOT be changed.
- COLUMN 4:
The Stream Size specifies the amount of data (in bytes) of each file to be indexed. For example, if the Stream Size for pdf files is set to the default 2048576 bytes (2MB) and the indexer encounters a 5MB pdf, less than half of the document will be indexed. Therefore, searches performed in Retain would not yield any results on words which are in the second half of the pdf. The entire document will be indexed if this value is changed to -1.
- COLUMN 5:
The File Size prevents the indexation of any file larger than the value specified. For example, if I set this value to 2048576 bytes (2MB), any files above this size will not be indexed.
Additional Information
This article was originally published in the GWAVA knowledgebase as article ID 1817.