Environment
Novell GroupWise 8
Novell GroupWise 7
Novell GroupWise 6.5
Novell GroupWise 6
Novell GroupWise 5.5
Novell NetWare 6.5
Novell NetWare 6.0
Novell NetWare 5.1
Situation
List of symptoms:
Client
1. Online users complain of slow client performance
2. Online users complain that they cannot login
3. Caching and remote users complain that updates do not occur or take a long time
Server: POA Console Screen
On the POA Console Screen look at the Status box. One will see information for Busy Threads and File Queues. The Busy Threads are divided by a ":" (colon). The first number will indicate the busy C/S (TCPHandler) threads. The second number will indicate the busy Message Worker Threads. The File Queues displays the total number of messages waiting in all message queues, when client/server information and message file information are displayed together.
1. C/S (TCPHandler) Threads will climb and stick
2. C/S (TCPHandler) Threads may max out at 99 on GroupWise 7 or 50 on GroupWise 8
3. Message Worker Threads will climb and stick
4. Message Worker Threads may max out at 30
5. File Queues will climb rapidly and process slowly
On the POA Console Screen look at Statistics Box. We are particularly interested in the Requests Pending statistic. This statistic displays the number of client/server requests from GroupWise clients the POA has not yet been able to respond to.
6. Requests Pending will climb and process slowly
Server: POA Web Console Screen
First Look at the Thread Status Box.
Thread Status | ||
Total | Busy | |
6 | 0 | |
6 | 0 | |
This will give you the same info that the POA Console Screen does for items 1 -4 above.
Also drill down on Normal Queues. You may see files building in queue 5.
Next look at the following statistics in the Statistics Box:
Next, check the POA Log Files:
Event Log Filter | |||||||
Events containing | |||||||
| |||||||
Search the log files for errors. You can do this by typing the word "error" in the field called "Events Containing" and then selecting the logs you want to search. You can also search log files from the POA Console Screen.
Although you are interested in all errors, for performance problems you want to focus on 820e (Cannot Lock File) errors. You won't always see these errors. However, they do indicate that the POA has a problem writing to a message store database.
Novell Remote Manager
In Novell Remote Manager (NRM) under the Diagnose Server section (top left of the screen) choose "Profile / Debug". You will see something like this:
Execution Profile Data by Thread | ||||
Thread Name | Thread ID | Thread State | Parent NLM | Execution Time |
958985A0 | Blocked on Semaphore | |||
984B84C0 | Blocked on a kernel CV | |||
Click on the link to view details of the Thread. On the stack look for NSS modules. NSS on the stack is an indication that the NSS filesystem is waiting on I/O to process. This is not a problem with GroupWise, NSS, or the OS. This is a problem with insufficient disk space or with hardware.
It is also possible to investigate whether there is a potential bottleneck with the disk subsystem.
Each NSS write request is placed in a NSS Write Queue, by default the size of this write queue is 1000.
As each request is processed by the disk subsystem a spot on the NSS Write Queue is made available for a new write request.
If the disk subsystem is older and slower or having trouble processing the write requests the NSS Write Queue can hit its maximum default value of 1000.
When this happens all subsequent write requests are unable to be placed in the write queue causing a backlog of requests resulting in users seeing slowness.
There are 2 different ways to view the NSS Write Queue state, the first is from within NetWare Remote Manager and the other is from the servers system console.
NetWare Remote Manager
Select Manage Server | View Statistics | Media Manager Statistical Information
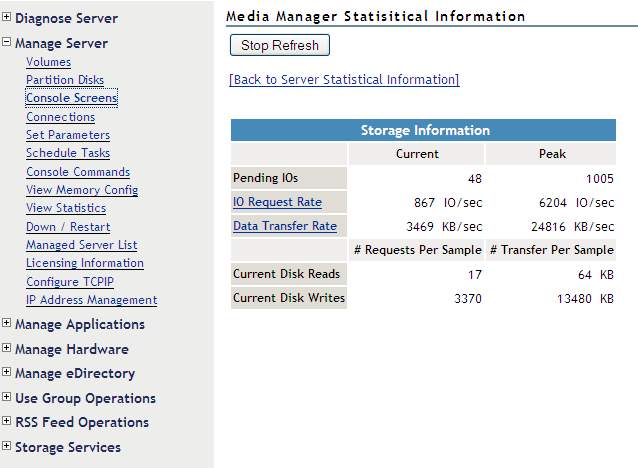
From this screen shot it is possible to see that there are currently 3,370 write requests in the Media Manager queue -- this queue holds requests for both NSS and for Traditional NetWare volumes (if they exist). This is a decent amount of work. If this workload continues, you will want to investigate further (see nss section below) to ascertain if NSS is getting backed up (i.e. too much work for the type of disk subsystem).
Server's System Console
nss /ZLSSIOStatus

This screen shot shows a server that has a major disk subsystem bottle neck and its users were experiencing a lot of slowness.
"Write count queue level" = 1000
This indicates that the NSS Write Queue is set to 1000.
"Pending Write IOs on queue" = 25665
This is the number of outstanding NSS write requests that are waiting to get in to the NSS Write Queue.
"Current Outstanding Write IOs" =1000
This indicates that there are currently 1000 NSS Write requests in the NSS Write Queue, i.e. it is maxed out.
nss /ZLSSPoolIOs=_summary
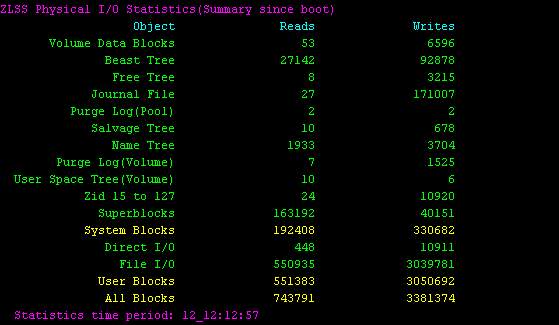
This command will allow you to see the cumulative reads and writes that have occurred since the server was booted.
In the screen shot above, that was taken from an infrequently used test server, you can see that there have been a total of 6,596 writes when looking at the "Volume Data Blocks" line.
If you wish to reset this information and monitor the NSS reads and writes going forward enter the following:
nss /ZLSSPoolIOr=_summary
Resolution
There are several issues that could cause performance problems. We will list them in order of ease of troubleshooting:
1. Rebuild the Post Office Database.
2. Copy view files from the \CLIENT directory in an updated (current) Software Distribution Directory into the Post Office's \OFVIEWS directory.
3. If you see 820e errors in the POA log file, verify the following:
2. Copy view files from the \CLIENT directory in an updated (current) Software Distribution Directory into the Post Office's \OFVIEWS directory.
3. If you see 820e errors in the POA log file, verify the following:
A. Backup is not running
B. Virus scanner is NOT scanning GroupWise Post Office Directories. Virus scanners should never scan GroupWise Post Office directories. This will cause database corruption and poor performance.
4. Verify GroupWise 3rd party applications are not using older API's and are using the SOAP protocol where appropriate.
5. Verify that the free disk space / total disk space ratio is at least .25 (25%). If your free disk space is below this value, add disk space.
6. For NetWare 5.1 and 6.0 servers please use the following TID https://support.microfocus.com/kb/doc.php?id=10065215&sliceId=&dialogID=10923764&stateId=0%200%2010929329 (Resolving GroupWise performance issues with NSS volumes)
If your GroupWise Post Office resides on a SAN please consider the following Best Practices and Troubleshooting.
Best Practices:
- GroupWise requires a throughput of at least 1 Gbps
- Document your SAN
- As a best practice, Novell does not recommend storing GroupWise data or running GroupWise Agents on/from a NAS or iSCSI. If this type of storage is used, then optimization is mandatory to insure a smooth running system.
- Use a single HBA vendor to decrease driver management pain.
- Use multiple HBAs for load balancing and failover.
- All parts should run at the same speed.
- Accurately lable your fibre cables. Update lables as changes are made.
- Do not mix 50-micron mulitmode fibre cable and 62.5-micron fibre cable. Novell recommends the use of 50-micon cable when using multimode.
- Do not bend or crimp the fibre cables. Remember that the cables are made of glass and that damage to the glass can cause loss of signal.
- Keep distances between the GroupWise server and SAN switch and the San switch and the Storage devices at no more than the stated maximum for the cable types you are using.
- Avoid the use of patch panels for the SAN. Using patch panel connections result in signal loss.
- Use a single vendor for your SAN switches.
- Decrease latency by minimizing the number of hops between a GroupWise Server and its data. The server should be no more than X hops from the data.
- Decrease latency by minimizing the distance between a GroupWise server and its data on the storage devices.
- Decrease GroupWise agent congestion by verifying that busy POAs and MTAs do not share the same path to storage.
- Also, avoid placing all GroupWise servers on a single SAN switch and the GroupWise data storage devices on a single switch. Doing so will also cause congestion on the SAN.
- Do not use SAN hubs and the FC-AL protocol to run GroupWise on a SAN. Instead use SAN switches and the FC-SW protocol.
- Use a single vendor for your disks and disk arrays.
Troubleshooting
- Call your SAN vendor for support
- Refer to the documentation that you created of your SAN
- Understand the flow of data from the server to the storage device